编译flink遇到的问题记录
今天编译flink遇到的几个问题简单的记录下。
1.第一个问题Blocked mirror for repositories
1 | Could not resolve dependencies for project |
我们maven3.8.1在以上版本默认会禁止非https的请求,我们需要降低版本,我使用了maven3.6.8版本
2.第二个问题,maven的settings.xml,可以使用阿里的
1 | <mirror> |

技术爱好者
今天编译flink遇到的几个问题简单的记录下。
1.第一个问题Blocked mirror for repositories
1 | Could not resolve dependencies for project |
我们maven3.8.1在以上版本默认会禁止非https的请求,我们需要降低版本,我使用了maven3.6.8版本
2.第二个问题,maven的settings.xml,可以使用阿里的
1 | <mirror> |
通过注解和aop来实现,后端的重复提交校验
1 |
|
1 |
|
1 |
|
有时候,我们在程序中不得不对某些方法进行重试,比如说,请求某个接口,如果我们每次,都通过while和count–的写法无疑会让代码,变的很不优雅。因此我们这边用spring的aop设计一下这个功能。
1 |
|
1 |
|
稍微解释一下下面的代码,我们around环绕,可以让我们在method执行之前对他进行拦截,然后只catch我们指定的RetryException,
对整个代码进行重新调用。
1 |
|
1 |
|
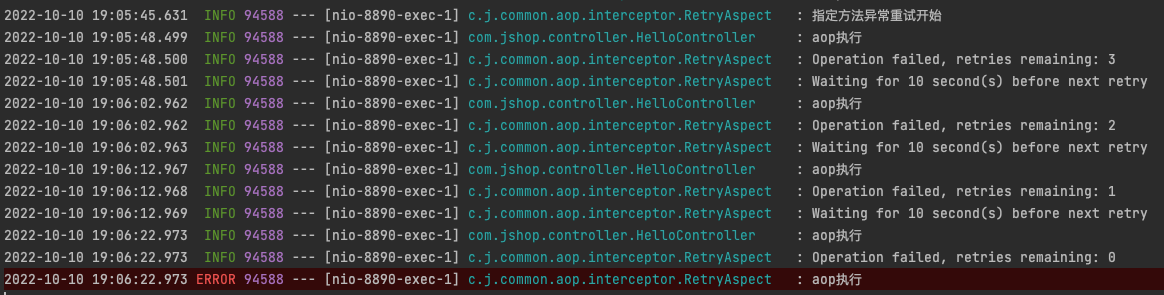
通过console打印结果,得到了我们需要的效果
笔者在写spring aop通过注解的时候,遇到了一些注解代码不执行的情况,所以写下这篇文档,记录下aop大部分算子的执行周期。
1 | /** |
1 |
|
1 |
|
查看打印结果:

由这个图我们可以看出来:
在方法不报错的情况下,执行顺序是 around => before => method执行 => afterReturning => after,
而在方法报错的情况下呢,

从上图我们可以看出执行顺序: around => before => method执行 => afterThrowing => after,
仔细观察两者,会发现区别只有在报错的时候执行的是afterThrowing,而成功的时候执行的是afterReturning。
Spring Aop Aspect的几个执行方法的顺序是:
Around => Before => Method => AfterReturning | AfterThrowing => After
Redis使用同一个Lua解释器来执行所有命令,同时,Redis保证以一种原子性的方式来执行脚本:当lua脚本在执行的时候,不会有其他脚本和命令同时执行,这种语义类似于 MULTI/EXEC。从别的客户端的视角来看,一个lua脚本要么不可见,要么已经执行完。
然而这也意味着,执行一个较慢的lua脚本是不建议的,由于脚本的开销非常低,构造一个快速执行的脚本并非难事。但是你要注意到,当你正在执行一个比较慢的脚本时,所以其他的客户端都无法执行命令。
1 | local c |
1 | /** |
1 | /** |
1 |
|
如上操作,我们通过下方的代码实现了流量限速,并且保证了原子性
1 | Number count = redisTemplate.execute(limitScript, keys, limitCount, limitPeriod); |
下面使我们的调用代码:
1 |
|
然后使我们的效果截图:

1 |
|
循环引用:
1 | // 循环引用的特殊情况,自引用 |
一般来说,存在循环引用问题的集合/对象在序列化时(比如Json化),如果不加以处理,会触发StackOverflowError异常。
分析原因:
当序列化引擎解析map1时,它发现这个对象持有一个map2的引用,转而去解析map2。解析map2时,发现他又持有map1的引用,又转回map1。如此产生StackOverflowError异常。
1 | //关闭FastJson的引用检测 |
1 | //在config上使用,只有我们引入redis包的时候,才会构建bean |
1 |
|
1 |
|
1 | #Mybatis-plus配置 |
1 |
|
@Cacheable可以标记在一个方法上,也可以标记在一个类上。
Spring会在其被调用后将其返回值缓存起来,以保证下次利用同样的参数来执行该方法时可以直接从缓存中获取结果,而不需要再次执行该方法。Spring在缓存方法的返回值时是以键值对进行缓存的,值就是方法的返回结果,至于键的话,Spring又支持两种策略,默认策略和自定义策略
需要注意的是当一个支持缓存的方法在对象内部被调用时是不会触发缓存功能的。
value属性是必须指定的,其表示当前方法的返回值是会被缓存在哪个Cache上的,对应Cache的名称。其可以是一个Cache也可以是多个Cache,当需要指定多个Cache时其是一个数组。
1 | //Cache是发生在cache1上的 |
key属性是用来指定Spring缓存方法的返回结果时对应的key的。该属性支持SpringEL表达式。当我们没有指定该属性时,Spring将使用默认策略生成key。我们这里先来看看自定义策略,至于默认策略会在后文单独介绍。
自定义策略是指我们可以通过Spring的EL表达式来指定我们的key。这里的EL表达式可以使用方法参数及它们对应的属性。使用方法参数时我们可以直接使用“#参数名”或者“#p参数index”。下面是几个使用参数作为key的示例。
1 |
|
除了上述使用方法参数作为key之外,Spring还为我们提供了一个root对象可以用来生成key。通过该root对象我们可以获取到以下信息。
| 属性名称 | 描述 | 示例 |
|---|---|---|
| methodName | 当前方法名 | #root.methodName |
| method | 当前方法 | #root.method.name |
| target | 当前被调用的对象 | #root.target |
| targetClass | 当前被调用的对象的class | #root.targetClass |
| args | 当前方法参数组成的数组 | #root.args[0] |
| caches | 当前被调用的方法使用的Cache | #root.caches[0].name |
当我们要使用root对象的属性作为key时,我们也可以将“#root”省略,因为Spring默认使用的就是root对象的属性。如:
1 |
|
有的时候我们可能并不希望缓存一个方法所有的返回结果。通过condition属性可以实现这一功能。condition属性默认为空,表示将缓存所有的调用情形。其值是通过SpringEL表达式来指定的,当为true时表示进行缓存处理;当为false时表示不进行缓存处理,即每次调用该方法时该方法都会执行一次。如下示例表示只有当user的id为偶数时才会进行缓存。
1 |
|
1 | //每次都会执行方法,并将结果存入指定的缓存中 |
@CacheEvict是用来标注在需要清除缓存元素的方法或类上的。
当标记在一个类上时表示其中所有的方法的执行都会触发缓存的清除操作。
@CacheEvict可以指定的属性有value、key、condition、allEntries和beforeInvocation。
其中value、key和condition的语义与@Cacheable对应的属性类似。即value表示清除操作是发生在哪些Cache上的(对应Cache的名称key表示需要清除的是哪个key,如未指定则会使用默认策略生成的key;condition表示清除操作发生的条件。
下面我们来介绍一下新出现的两个属性allEntries和beforeInvocation。
allEntries是boolean类型,表示是否需要清除缓存中的所有元素。默认为false,表示不需要。当指定了allEntries为true时,Spring Cache将忽略指定的key。有的时候我们需要Cache一下清除所有的元素,这比一个一个清除元素更有效率。
1 |
|
清除操作默认是在对应方法成功执行之后触发的,即方法如果因为抛出异常而未能成功返回时也不会触发清除操作。使用beforeInvocation可以改变触发清除操作的时间,当我们指定该属性值为true时,Spring会在调用该方法之前清除缓存中的指定元素。
1 |
|
@Caching注解可以让我们在一个方法或者类上同时指定多个Spring Cache相关的注解。其拥有三个属性:cacheable、put和evict,分别用于指定@Cacheable、@CachePut和@CacheEvict。
1 |
|
笔者最近从go zero框架写的代码中获得不小启发。所以写出一个文档用来总结,并且尝试把go zero的这些并发特性,用spring boot实现。
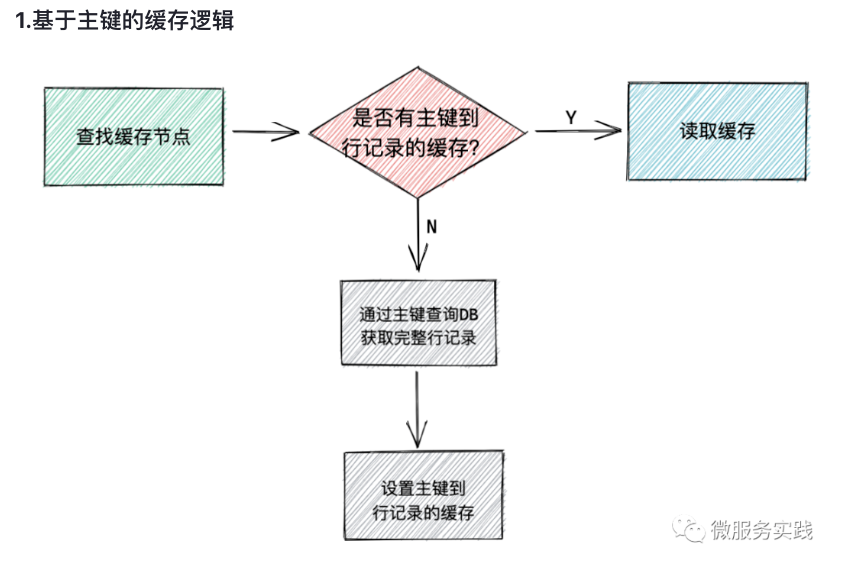
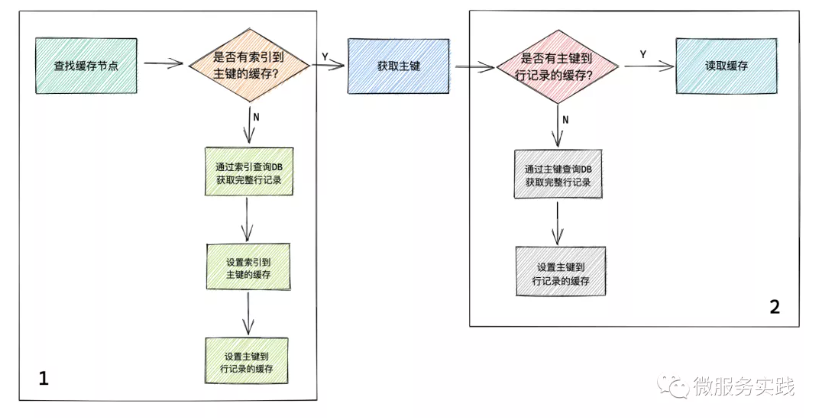
代码分为两个block,
在block1当中:
找到索引和主键的缓存的情况:
找不到索引和主键的缓存情况:
1 | type Content struct { |
cache 实现的功能包括
缓存击穿是指访问某个非常热的数据,缓存不存在,导致大量的请求发送到了数据库,这会导致数据库压力陡增,缓存击穿经常发生在热点数据过期失效时,如下图所示:

既然缓存击穿经常发生在热点数据过期失效的时候,那么我们不让缓存失效不就好了,每次查询缓存的时候不要使用Exists来判断key是否存在,而是使用Expire给缓存续期,通过Expire返回结果判断key是否存在,既然是热点数据通过不断地续期也就不会过期了
还有一种简单有效的方法就是通过singleflight来控制,singleflight的原理是当同时有很多请求同时到来时,最终只有一个请求会最终访问到资源,其他请求都会等待结果然后返回。获取商品详情使用singleflight进行保护示例如下:
1 | func (l *ProductLogic) Product(in *product.ProductItemRequest) (*product.ProductItem, error) { |
缓存穿透是指要访问的数据既不在缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据。此时也就没办法从数据库中读出数据再写入缓存来服务后续的请求,类似的请求如果多的话就会给缓存和数据库带来巨大的压力。
针对缓存穿透问题,解决办法其实很简单,就是缓存一个空值,避免每次都透传到数据库,缓存的时间可以设置短一点,比如1分钟,其实上文已经有提到了,当我们访问不存在的数据的时候,go-zero框架会帮我们自动加上空缓存,比如我们访问id为999的商品,该商品在数据库中是不存在的。
缓存雪崩时指大量的的应用请求无法在Redis缓存中进行处理,紧接着应用将大量的请求发送到数据库,导致数据库被打挂,好惨呐!!缓存雪崩一般是由两个原因导致的,应对方案也不太一样。
第一个原因是:缓存中有大量的数据同时过期,导致大量的请求无法得到正常处理。
针对大量数据同时失效带来的缓存雪崩问题,一般的解决方案是要避免大量的数据设置相同的过期时间,如果业务上的确有要求数据要同时失效,那么可以在过期时间上加一个较小的随机数,这样不同的数据过期时间不同,但差别也不大,避免大量数据同时过期,也基本能满足业务的需求。
第二个原因是:Redis出现了宕机,没办法正常响应请求了,这就会导致大量请求直接打到数据库,从而发生雪崩
针对这类原因一般我们需要让我们的数据库支持熔断,让数据库压力比较大的时候就触发熔断,丢弃掉部分请求,当然熔断是对业务有损的。
在go-zero的数据库客户端是支持熔断的,如下在ExecCtx方法中使用熔断进行保护
1 | func (db *commonSqlConn) ExecCtx(ctx context.Context, q string, args ...interface{}) ( |
1 |
|
1 | import java.util.HashMap; |
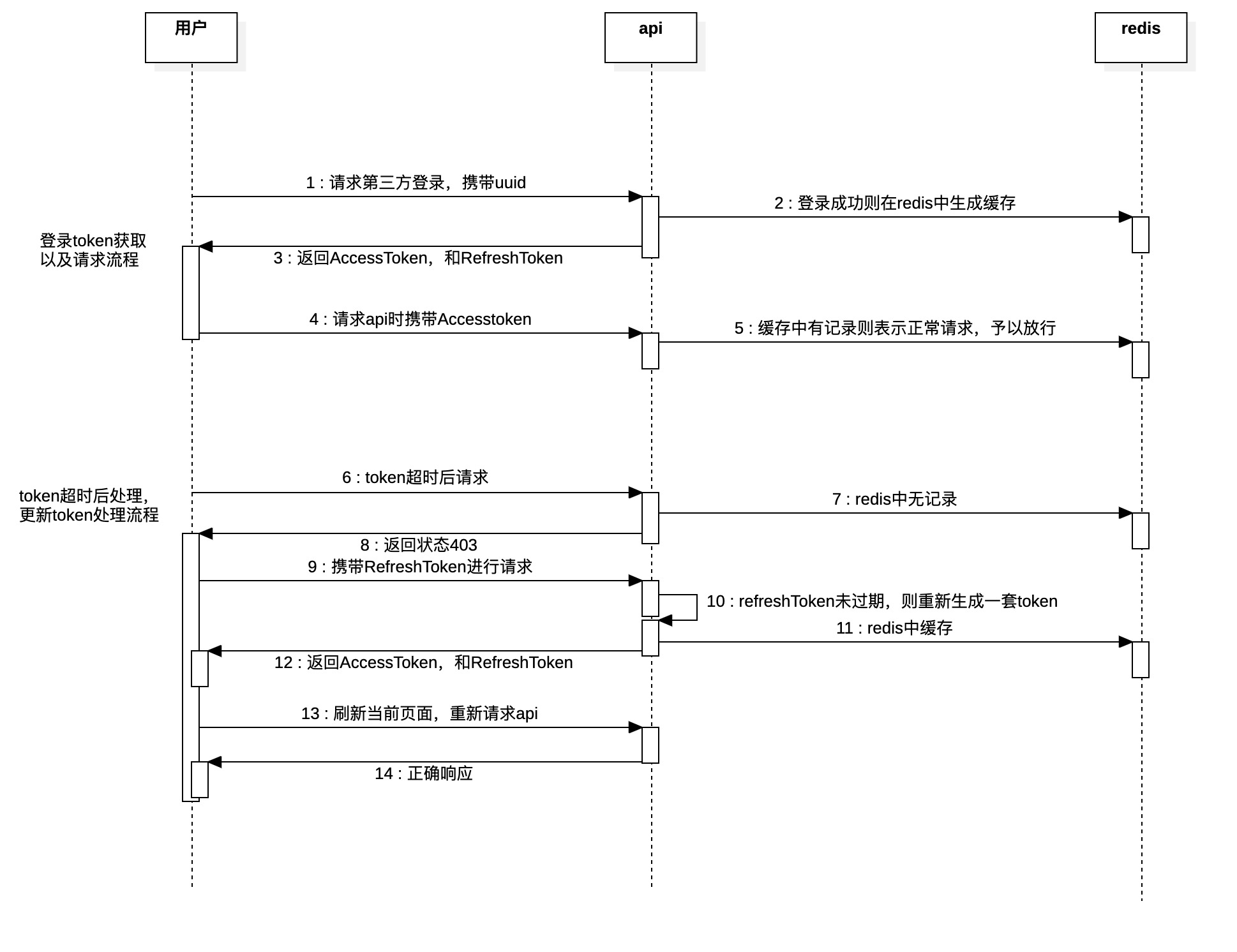

1、携带uuid与服务端交互,服务端记录唯一id,并且将第三方登录地址返回
2、将第三方返回的信息在redis缓存中记录,
3、返回accesstoken(访问token),以及refreshtoken(过期刷新token)
4、请求api时携带accesstoken
5、服务端校验时,将前端token带入到redis中进行判定,如果存在则认为是前端的正常请求,予以放行
刷新token
6、携带过期accesstoken请求后段,
7、api查验发现redis中没有token记录
8、返回403状态
9、前端判定到403状态,携带refreshtoken去请求刷新token接口
10、判定redis中的refreshtoken是否有效
11、根据refreshtoken中信息,从新构建accesstoken以及refreshtoken
12、返回accesstoken(访问token),以及refreshtoken(过期刷新token)
13、前端刷新当前页面,重新请求api
14、正确响应
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true